[Algorithm Question] Finding the origin of a Computer Virus from the given list of machine pairs

![[Algorithm Question] Finding the origin of a Computer Virus from the given list of machine pairs](/content/images/size/w2000/2020/11/cso_security_threat_virus_malicious_binary_code_bluebay2014_gettyimages-983223752_2400x1600-100801546-large.jpg)
Recently, I worked on the algorithm problem that required to find the origin of computer virus given the list of infected machine pairs. In general you're given the input in the form of computer pairs (a, b) which indicates the virus infection from machine a to machine b. The goal is to find the machine where the infection started.
Let's take a look at sample input and corresponding graph of virus propagation,
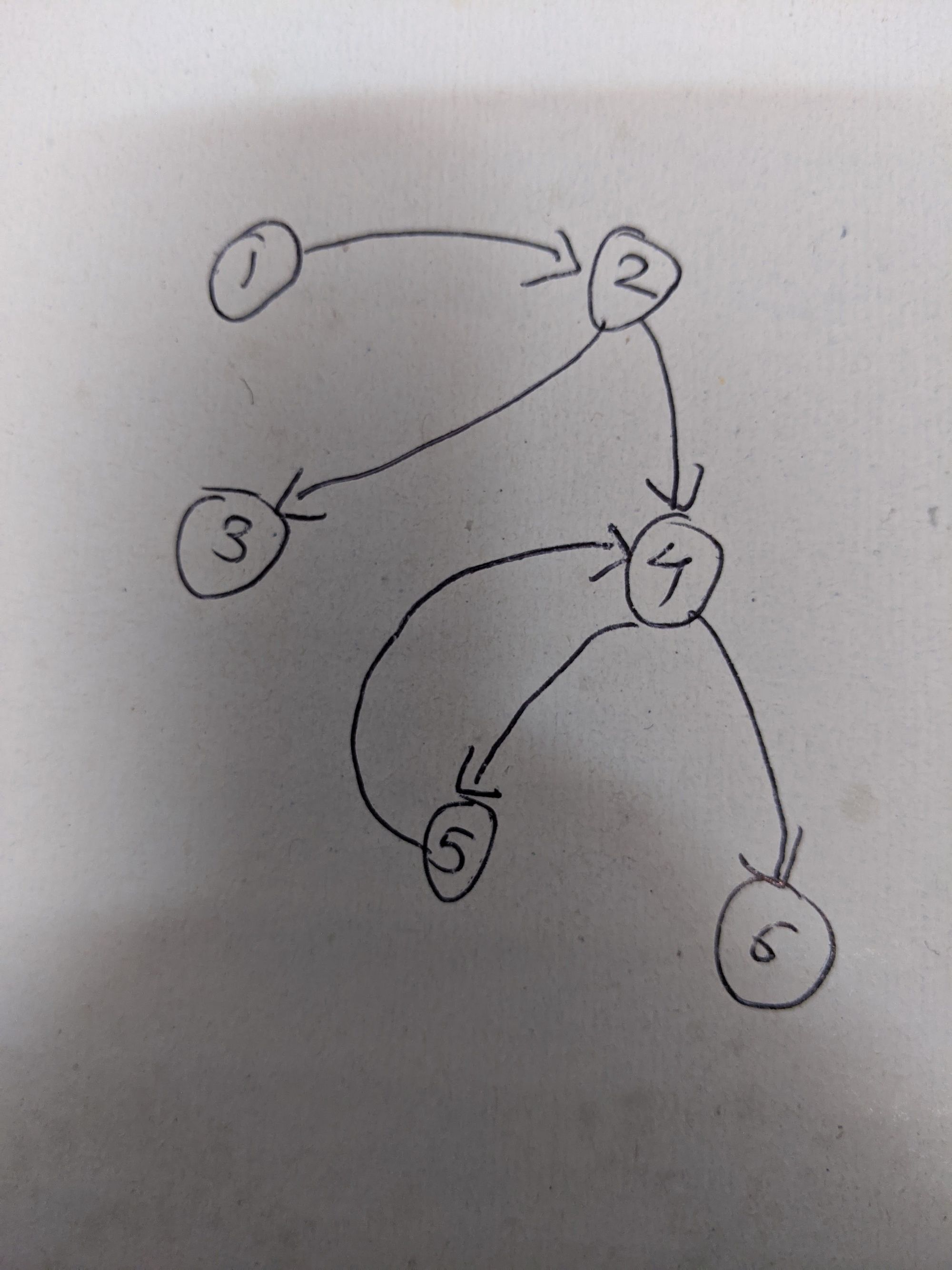
For this graph our input will be,
(1, 2), (2, 3), (2, 4), (4, 5), (4, 6), (5, 4)
The expected output is node 1 where this virus originated and eventually propagated to other nodes.
The first answer that may come to your mind is topological sorting where all the nodes are traversed in the same order they appear in the graph. This is true only if graph was acyclic. In our case there is no guarantee that virus may infect the already infected machine causing cycle. Like cycle 4-5-4 in above case.
Thus we will employ different approach - We will keep track of inbound and outbound edges for all the node pairs. Then we will iterate over them and find only the node with no incoming edge. This will be the one where virus originated. Let's write the algorithm first,
For each graph pair
Add source node to dictionary if it does not already exist and initialize its value to zero
If destination node already exists in the dictionary
Increment the count associated with destination node's key
Else
Add the destination node to dictionary as a key and initialize its value to 1
Iterate over the dictionary
For each key check the value
if the value associated with key is zero, return that node as a node where virus originatedThis solution is based on the assumption that every node that receives a virus should have inbound link from other node unless that node is where virus originated. Since we are maintaining a dictionary as a means of counting inbound links, the node with zero inbound links is the originator. This solution will work even if graph has cycles.
The full source code with solution is available in this Github gist. The idea is the same as I mentioned in the algorithm except this is the full implementation in Swift language.
Time and Space Complexity:
As with any algorithm related problem, we will analyze its time and space complexity. We are iterating over graph pairs once. Assuming number of graph pairs is m. The time complexity of first for-loop is O(m). Second time we're iterating over the dictionary. The size of dictionary is n, where n is the average number of nodes in the graph. So time complexity of second for loop is O(n). Since these two for loops are run separately, the time complexity of our algorithm is,
O(m + n) where m is total number of pairs and n is average number of nodes in the graph.
As for space complexity, we are maintaining a dictionary to store node to incoming edges count mapping. Assuming n is the average number of nodes in graph, the space complexity of algorithm is O(n)
Credits:
Thanks to Swarali Raut (@hsp_raut) for suggesting the correct and final solution while I was scrambling with complicated and mostly incorrect approach

